Tästä tulee onnellinen sotku suomea ja englantia, pahoittelut. Tavoite on ymmärtää, mitä kielimallin kouluttaminen tarkoittaa (Large Language Model = LLM). Merkitsen pallukoilla (ranskalaisilla viivoilla) otteita wikipediasta (myös tuon linkin johdannaissivuilta) ja kirjoitan, miten asian ymmärrän. Jätän wikin linkit paikoilleen. Yritän myös hahmottaa hieman sitä, miten nykyisiin malleihin päästiin. Ja tässä miellän tekoälyn prosessina, jolla yritetään imitoida ihmisen vasteita tekstiin/puheeseen.
Perusideoita (englanniksi)
- The largest and most capable LLMs are generative pre-trained transformers (GPTs) and provide the core capabilities of modern chatbots.
- In 2018, researchers first proposed that all previously separate tasks in natural language processing (NLP) could be cast as a question-answering problem over a context. In addition, they trained a first single, joint, multi-task model that would answer any task-related question like “What is the sentiment” or “Translate this sentence to German” or “Who is the president?”
- The AI boom saw an increase in the amount of “prompting technique” to get the model to output the desired outcome and avoid nonsensical output, a process characterized by trial-and-error. After the release of ChatGPT in 2022, prompt engineering was soon seen as an important business skill, albeit one with an uncertain economic future.
- Reinforcement learning, particularly policy gradient algorithms, has been adapted to fine-tune LLMs for desired behaviors beyond raw next-token prediction.
- While supervised learning and unsupervised learning algorithms respectively attempt to discover patterns in labeled and unlabeled data, reinforcement learning involves training an agent through interactions with its environment. To learn to maximize rewards from these interactions, the agent makes decisions between trying new actions to learn more about the environment (exploration), or using current knowledge of the environment to take the best action (exploitation). The search for the optimal balance between these two strategies is known as the exploration–exploitation dilemma.
Yritys ymmärtää asia suomeksi
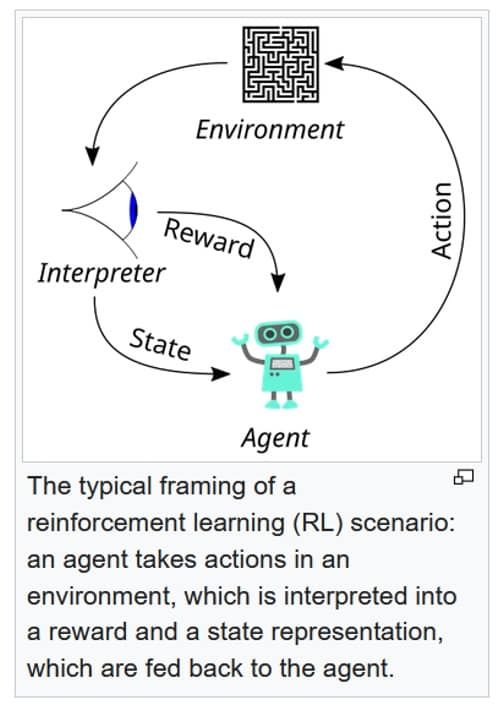
Voisiko maallikko ymmärtää tämän siten, että tuo oheinen vihreä tekoälyagentti on massiivinen määrä tekstiä ja lauseita järjestettynä tavallaan tietokannaksi tai verkoksi, joissa sanat ja lauseet viittaavat toisiinsa. Ja eri viittauksilla on eri painotuksia. Jos tekoälyn käyttäjä antaa agentille täydennettäväksi lauseen “Musti on” niin sanaa “koira” on käytetty koulutusmateriaaliassa paljon enemmän kuin sanaa “kissa” tai “kilpikonna”, joten “koira” -sanan painotus on vahvin. Näin tekoäly arvaa kysyjän tarkoittavan koiraa ja tuottaa vastaavan lauseen kysyjälle (eli kuvassa “Ympäristöön”).
Menetelmään voi näköjään olla rakennettuna palautemekanismi, jolla tekoäly yrittää käyttäjän seuraavista lauseista päätellä, tyydyttikö vastaus lukijaa. Jos näin kävi, menetelmään liittyvä palkitsemistoiminto vahvistaa kyseisiä painotuksia, mutta ilmeisesti on myös olemassa tekoälymalleja, jotka käyttävät tuota “exploitation”-strategiaa, jossa luotetaan ainoastaan alkuperäiseen koulutusmateriaaliin,
Prompting – tämä lienee oleellinen koulutustapa
Lause “… ‘prompting technique’ to get the model to output the desired outcome …” on mielenkiintoinen, koska olen useassa otteessa jo törmännyt tähän. Olen ymmärtänyt sen tavallaan tekoälyn operaattoreiden (tai “katselijoiden”, kuten kuulemma joku tekoälymalli on ihmiset nimennyt) menetelmäksi vahvistaa joitain tiettyjä painotuksia, kun tekoäly on antanut ongelmallisia vastauksia. Kun esimerkiksi kirjallisuudessa ja teksteissä käsitellään paljon itsemurhia, saattaisi tekoäly löytää tämän ehdotukseksi käyttäjän ongelmiin. Tekoälyllä kun ole mitään motiivia eikä kykyä ymmärtää sitä valtavaa kärsimyksen määrää, joka tällaisesta ratkaisusta ympärille syntyisi. Käsittääkseni operaattorilla ei ole menetelmää pakottaa ohjetta “Älä ikinä ehdota käyttäjälle, että hänen pitäisi tehdä itsemurha” sen käyttäytymismalliin, mutta operaattori voi prompteillaan muokata painotuksia niin vahvoiksi, että käytännössä kyseinen tekoälymalli ei enää tätä enää tee (ellei joku mekanismi taas muuta painotuksia). Yritän jatkossa ymmärtää tätä prompting-menetelmää enemmän. Yksi kysymys on, voiko asiansa osaava normaali tekoälyn käyttäjä sopivalla kysely/palaute -menettelyllä ohjata painotuksia haluamaansa suuntaan – silloin kun tekoäly käyttää oppimisessaan “exploration”-strategiaa.
Onko sama kielimalli eri tekoälyversioissa
Toinen mielenkiintoinen asia on, onko esimerkiksi yritysten Suomessakin käyttämissä tekoälyagenteissa sama peruskoulutus, kuin vaikka Microsoftin Copilotin käyttämässä agentissa. Kun katson OpenAI:n myyntisivuja, siellä kerrotaan näin:
- The o-series of models are trained with reinforcement learning to think before they answer and perform complex reasoning. The o3-pro model uses more compute to think harder and provide consistently better answers.
- o3-pro is available in the Responses API only to enable support for multi-turn model interactions before responding to API requests, and other advanced API features in the future. Since o3-pro is designed to tackle tough problems, some requests may take several minutes to finish. To avoid timeouts, try using background mode.
Eli tämän perusteella veikkaisin, että o3-mallin peruskoulutusmateriaali on sama kaikissa versioissa. Mutta tämä vaatinee lisää selvitystä.
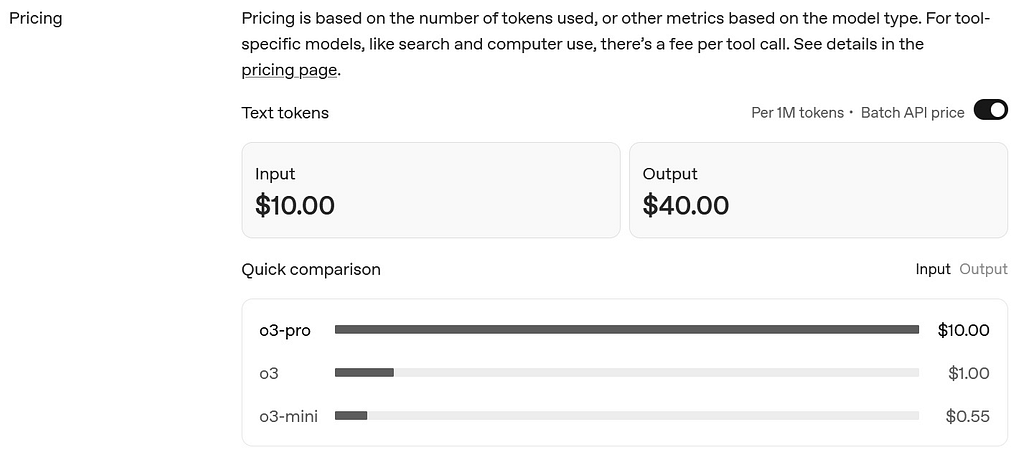
Ja siis miljoona input-tokenia maksaa 10$ ja miljoona output-tokenia 40$ ? Mitä ikinä tuo tarkoittaakin, ei kuulosta kalliilta 😮 Pitäisiköhän ostaa API-pohjainen versio tämän selvitysprojektin käyttöön? (… saisin varmaan mustan silmän jälkikasvulta 😅)
Näihin ajatuksiin on hyvä keskeyttää tällä erää.
Yhteenveto matkakertomuksen osista löytyy tästä ja muut osat tähän mennessä ovat:
- Osa 1: Kokemukseni tekoälystä tähän mennessä
- Osa 3: Miksi tutkia tekoälyn riskejä
- Osa 4: Mikä on OpenClaw, joka teki oman Facebookin
- Osa 5: Tekoälyn vastuullinen hyödyntäminen
- Osa 6: Romahduttaako tekoäly SaaS-hinnoittelun
- Osa 7: Rauhoittuuko tekoälyn kehitysvauhti
Kerään linkit näihin blogikirjoituksiini sivulle “Mitä tekoäly on“.
0 Comments